参赛链接:https://aiarena.tencent.com/aiarena/zh
2024 智能体博弈赛道 2024 年,是我第一次接触到强化学习,对于一些概念都比较陌生,今年的比赛本质上是进行调参。(2025 年会狠狠的怀念的)。
2024 年,我们改进方向主要是进行奖励函数的改进,在此基础上加入了很多的奖励函数,想要让模型变的更加的聪明,但是事与愿违,增多奖励函数非常容易让模型变的十分抽象,并且新加的奖励函数容易让模型退化,并且由于训练是 self-play,及其容易出现 lazy-agent 的现象,具体表现就是两边都躲在草丛里面,清完兵线就没有任何的动作了。此外,还导致训练过程中梯度爆炸的限制,主要原因就是没有对奖励值得大小进行约束,导致一个值变的非常的大。
因此,奖励函数设计也变得十分的烧脑,并且尽可能得保证零和博弈。同时,样本的丰富性和多样性就很重要了,之前有选手就写了 ELO 机制,另外,腾讯开悟框架也提供了 random 方法随机选择模型池里面的的模型,但是有选手说好像不行,不能用,但是我能用,很奇怪,我没有看懂腾讯的分布式框架,具体用没用上我也不清楚了。
self-play : 自我博弈(Self-Play)是应用于智能体于智能体之间处于对抗关系的训练方法,这里的对抗关系指的是一方的奖励上升必然导致另一方的奖励下降。通过轮流训练双方的智能体就能使得双方的策略模型的性能得到显著提升,使得整个对抗系统达到正和博弈的效果。[1] [2] lazy agent :Lazy Agent 是指在稀疏或不合理的奖励结构下,智能体因缺乏激励而选择被动或无所作为的策略,从而降低整体性能的现象。(在这里面应该就是推塔了)ELO : ELO等级分的原理 ELO等级分的计算则是从一个时间点开始有一个初始分,然后随着每次比赛,根据比赛结果和对手的等级分,进行自己等级分的修正,进而在多次比赛后收敛得到接近选手真实水平的积分。 即使粗略看比赛成绩表,也能够看出选手的表现是有起伏的,也就是有“状态”之分。强手未必恒定表现好于弱手;每人之状态在不同的日子不同的比赛里都会有好 坏不同。而总的来说整个生涯里每一点上,一名选手的表现将大致围绕在某个平均水平上下波动,有时会有背离,而出现大背离的情况比出现小背离的情况频率要低 [3]
最后的话,调参是门手艺活,但是 2024 年包括 2025 我感觉还是没太学会。并且感觉接收深度学习这方面知识有点抗拒,这在 2025 年也有所体现,感觉一个人打这种比赛还是容易变的非常的保守。
参考资料
https://tianjuehai.github.io/tianjuehai/2024/06/21/%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E4%B8%AD%E7%9A%84%E8%87%AA%E6%88%91%E5%8D%9A%E5%BC%88%EF%BC%88self-play%EF%BC%89/ https://zhuanlan.zhihu.com/p/564431683 https://blog.csdn.net/weixin_43679037/article/details/121855591
2025 智能体博弈赛道 2025 年,是我第二次参加腾讯开悟,主要选择了智能体博弈赛道中级和高级,当然也被拉去做了 AI 算子开发,但是貌似没有什么完成度,纯属挂名。
今年的赛道感觉很难,而且特别吃经验,今年主要的任务为:
工作量比去年大了很多,但是比较吃经验,去年由于我没有认真看,光瞎改奖励函数,导致浪费了一周时间在 MLP 上,因为 MLP 训练速度非常的快,导致我认为 MLP 应该是够达到比较好的水平了,目前是最后一周,明显感受到已经 MLP 的上限 (baseline 7),算是有点小固执吧。
由于官方并没有完全删除掉 LSTM。因此,其实可以直接复制去年的模型过来,然后对应的特征设计就行,但是我规划出现了问题,导致没有采用这个方法,之后与一些选手交流,感觉还是抱着腾讯的大腿才是最优解。
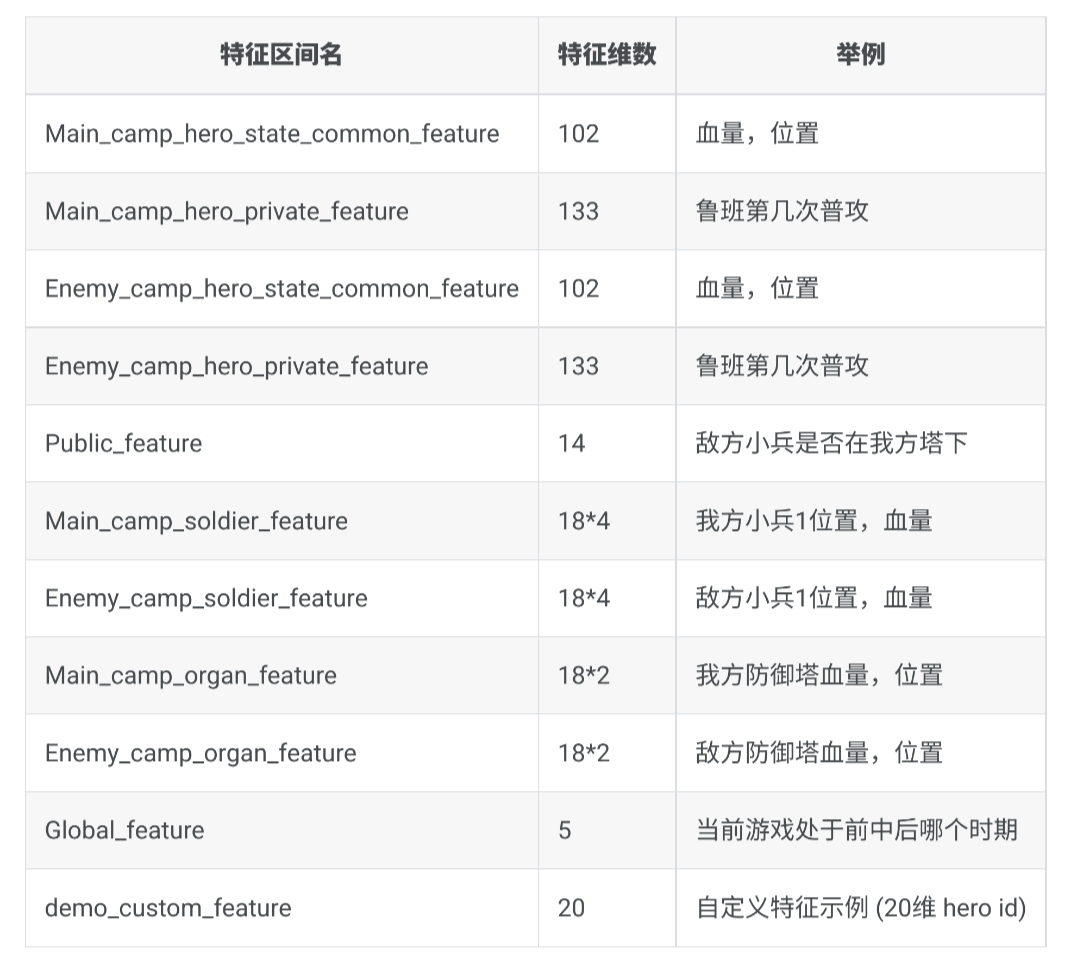
特征处理 特征处理我写的十分的杂糅,没有进行特别的分类处理,简单的分成了:
双方英雄特征: 196 * 2
双方 NPC 特征:
spring * 1
tower * 1
crystal * 1
soldier * 4
monster * 1
但是怎么说呢,非常的乱,也没有特别进行处理,导致特征工程其实做的比较烂。
社区中有人分享相关的特征设计,后面由于各种各样的事情没有开始动工。
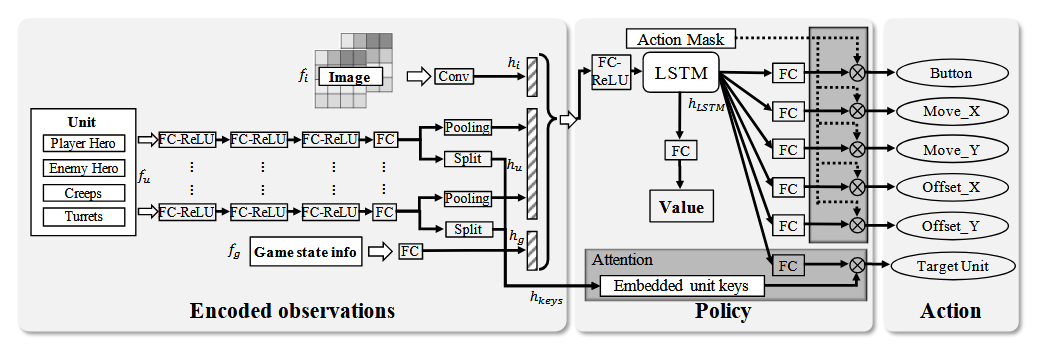
模型设计 中级赛道模型主要是采取 MLP,并对其进行了一些优化:
另外,还增加了 values model 和 policy model 的参数,使其拟合能力更强。
但是,可以参考有 LSTM 的方法,并且有现成的代码可以直接使用:algorithm_torch.py ,只需要对特征进行适配就行。
奖励函数设计 奖励函数没有进行专门的设计,主要还是沿用去年的 baseline,具体的实现已经有佬发过,https://luoxi2334.oss-cn-shanghai.aliyuncs.com/reward_process.py。
在此基础上,我还增加了伤害的奖励机制,感觉是有效果的,但是在训练后期明显觉察权重过高,当想拉低的时候发现时间已经到达尾声。
优化上面采取了类似课程学习的方法(这在社区中有所提及),采用了分阶段的奖励机制,有一定的提升:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def calc_reward_weight (self, frame_data, reward_name, weight ): value = 0.0 frame_no = frame_data["frameNo" ] time_args = frame_no / 1800 if reward_name == "tower_hp_point" : value = min (12.0 , 3.0 * time_args) elif reward_name == "money" : value = max (0.015 - time_args * 0.0015 , 0.006 ) elif reward_name == "exp" : value = max (0.0075 - 0.0009 * time_args, 0.0 ) elif reward_name == "ep_rate" : value = max (0.0 , 1.0 - 0.1 * time_args) elif reward_name == "death" : value = max (-1.5 , -0.2 * time_args - 0.5 ) elif reward_name == "last_hit" : value = max (0.8 - 0.05 * time_args, 0.2 ) elif reward_name == "forward" : value = min (0.02 , time_args * 0.005 ) else : value = weight return value
调参 已经被调参折磨死了,PPO 虽然参数不是特别多,但是还是特别折磨,主要需要调节的参数有:
1 2 3 4 5 6 7 8 9 10 11 12 13 INIT_LEARNING_RATE_START = 1e-3 TARGET_LR = 1e-4 TARGET_STEP = 5000 BETA_START = 0.025 GAMMA = 0.995 LAMDA = 0.95
PPO loss 的计算方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 # loss of value net # 值网络的损失 fc2_value_result_squeezed = value_result.squeeze(dim=1) # 均方误差 self.value_cost = 0.5 * torch.mean(torch.square(reward - fc2_value_result_squeezed), dim=0) # 优势函数计算 new_advantage = reward - fc2_value_result_squeezed # 使用 advantage 的均方误差形式 self.value_cost = 0.5 * torch.mean(torch.square(new_advantage), dim=0) # for entropy loss calculate # 用于熵损失计算 label_logits_subtract_max_list = [] label_sum_exp_logits_list = [] label_probability_list = [] epsilon = 1e-5 # policy loss: ppo clip loss # 策略损失:PPO剪辑损失 self.policy_cost = torch.tensor(0.0) for task_index in range(len(self.is_reinforce_task_list)): if self.is_reinforce_task_list[task_index]: final_log_p = torch.tensor(0.0) # 屏蔽非法动作 boundary = torch.pow(torch.tensor(10.0), torch.tensor(20.0)) # 动作选择 one_hot_actions = nn.functional.one_hot(label_list[task_index].long(), self.label_size_list[task_index]) # 屏蔽非法动作 legal_action_flag_list_max_mask = (1 - legal_action_flag_list[task_index]) * boundary # 归一化 label_logits_subtract_max = torch.clamp( label_result[task_index] - torch.max( label_result[task_index] - legal_action_flag_list_max_mask, dim=1, keepdim=True, ).values, -boundary, 1, ) label_logits_subtract_max_list.append(label_logits_subtract_max) # 合法动作的指数概率 label_exp_logits = ( legal_action_flag_list[task_index] * torch.exp(label_logits_subtract_max) + self.min_policy ) label_sum_exp_logits = label_exp_logits.sum(1, keepdim=True) label_sum_exp_logits_list.append(label_sum_exp_logits) label_probability = 1.0 * label_exp_logits / label_sum_exp_logits label_probability_list.append(label_probability) # 计算当前动作的概率 policy_p = (one_hot_actions * label_probability).sum(1) policy_log_p = torch.log(policy_p + epsilon) # 旧策略概率(来自经验回放 / 上一次迭代) old_policy_p = (one_hot_actions * old_label_probability_list[task_index] + epsilon).sum(1) old_policy_log_p = torch.log(old_policy_p) # 概率比 (new/old) final_log_p = final_log_p + policy_log_p - old_policy_log_p ratio = torch.exp(final_log_p) # clip 防止比率过大 clip_ratio = ratio.clamp(0.0, 3.0) surr1 = clip_ratio * advantage surr2 = ratio.clamp(1.0 - self.clip_param, 1.0 + self.clip_param) * advantage temp_policy_loss = -torch.sum( torch.minimum(surr1, surr2) * (weight_list[task_index].float()) * 1 ) / torch.maximum(torch.sum((weight_list[task_index].float()) * 1), torch.tensor(1.0)) # 累加多个任务的策略损失 self.policy_cost = self.policy_cost + temp_policy_loss # cross entropy loss # 交叉熵损失 current_entropy_loss_index = 0 entropy_loss_list = [] for task_index in range(len(self.is_reinforce_task_list)): if self.is_reinforce_task_list[task_index]: # 熵 = -Σ p * log(p),用于增加策略多样性 temp_entropy_loss = -torch.sum( label_probability_list[current_entropy_loss_index] * legal_action_flag_list[task_index] * torch.log(label_probability_list[current_entropy_loss_index] + epsilon), dim=1, ) # 加权平均 temp_entropy_loss = -torch.sum( (temp_entropy_loss * weight_list[task_index].float() * 1) ) / torch.maximum(torch.sum(weight_list[task_index].float() * 1), torch.tensor(1.0)) entropy_loss_list.append(temp_entropy_loss) current_entropy_loss_index = current_entropy_loss_index + 1 else: # 非强化学习任务的熵损失为 0 temp_entropy_loss = torch.tensor(0.0) entropy_loss_list.append(temp_entropy_loss) self.entropy_cost = torch.tensor(0.0) for entropy_element in entropy_loss_list: self.entropy_cost = self.entropy_cost + entropy_element self.entropy_cost_list = entropy_loss_list # PPO 总损失 = value loss + policy loss + β * entropy loss self.loss = self.value_cost + self.policy_cost + self.var_beta * self.entropy_cost return self.loss, [ self.loss, [self.value_cost, self.policy_cost, self.entropy_cost], ]
分为三个阶段:
训练前期:可以使用大学习率,高探索度梭哈。
训练中期:逐步减小学习率,根据情况降低探索度
训练后期:继续减小学习率,最小可以到达 1e-6,可以加大 GAMMA,让模型更加远见,但是可能会丢失掉一些短期最优解。
另外还有 sleep time 和 batchsize。其中 sleep time 主要是控制样本呢产生和消耗,防止多次利用历史数据,导致过拟合等情况,但是 sleep time 过大容易导致训练缓慢。batchsize 在后期可以拉大,稳定训练。
施法动作 今年没有做这部分上的工作,因为我不太清楚具体的方法,但是和其他佬分享的时候发现可以通过这种方法来加速训练,包括但不限于卡线,吃血包,回城。
具体的实现方法就是直接操作合法动作空间,来协助训练,具体方法略。