GMP
总述
以下这部分是直接截取的腾讯技术工程的帖子中的内容。
为了解决 Go 早期多线程 M 对应多协程 G 调度器的全局锁、中心化状态带来的锁竞争导致的性能下降等问题,Go 开发者引入了处理器 P 结构,形成了当前经典的 GMP 调度模型;
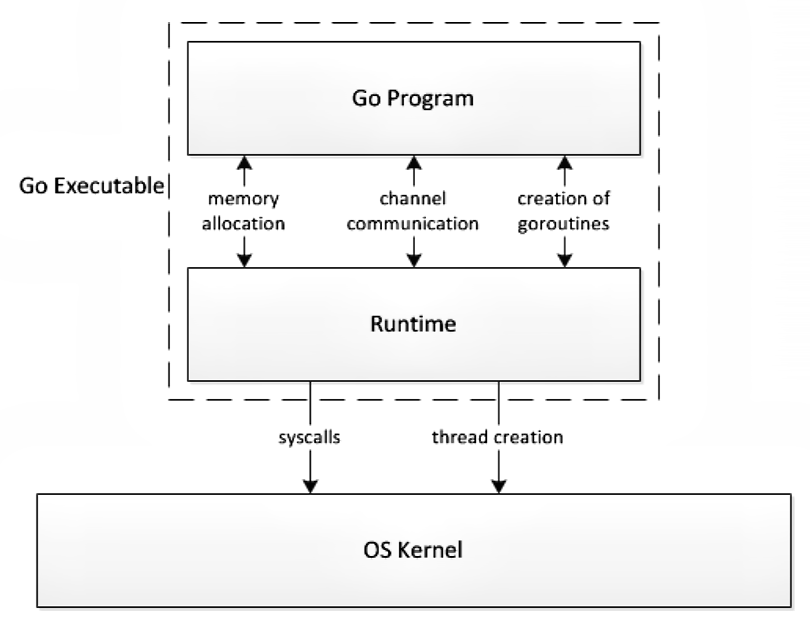
Go 调度器是指:运行时在用户态提供的多个函数组成的一种机制,目的是高效地调度 G 到 M上去执行;
Go 调度器的核心思想是:尽可能复用线程 M,避免频繁的线程创建和销毁;利用多核并行能力,限制同时运行(不包含阻塞)的 M 线程数 等于 CPU 的核心数目; Work Stealing 任务窃取机制,M 可以从其他 M 绑定的 P 的运行队列偷取 G 执行;Hand Off 交接机制,为了提高效率,M 阻塞时,会将 M 上 P 的运行队列交给其他 M 执行;基于协作的抢占机制,为了保证公平性和防止 Goroutine 饥饿问题,Go 程序会保证每个 G 运行 10ms 就让出 M,交给其他 G 去执行,这个 G 运行 10ms 就让出 M 的机制,是由单独的系统监控线程通过 retake() 函数给当前的 G 发送抢占信号实现的,如果所在的 P 没有陷入系统调用且没有满,让出的 G 优先进入本地 P 队列,否则进入全局队列;基于信号的真抢占机制,Go1.14 引入了基于信号的抢占式调度机制,解决了 GC 垃圾回收和栈扫描时无法被抢占的问题;
由于数据局部性,新创建的 G 优先放入本地队列,在本地队列满了时,会将本地队列的一半 G 和新创建的 G 打乱顺序,一起放入全局队列;本地队列如果一直没有满,也不用担心,全局队列的 G 永远会有 1/61 的机会被获取到,调度循环中,优先从本地队列获取 G 执行,不过每隔61次,就会直接从全局队列获取,至于为啥是 61 次,Dmitry 的视频讲解了,就是要一个既不大又不小的数,而且不能跟其他的常见的2的幂次方的数如 64 或 48 重合;
M 优先执行其所绑定的 P 的本地运行队列中的 G,如果本地队列没有 G,则会从全局队列获取,为了提高效率和负载均衡,会从全局队列获取多个 G,而不是只取一个,个数是自己应该从全局队列中承担的,globrunqsize / nprocs + 1;同样,当全局队列没有时,会从其他 M 的 P 上偷取 G 来运行,偷取的个数通常是其他 P 运行队列的一半;
G 在运行时中的状态可以简化成三种:等待中_Gwaiting、可运行_Grunnable、运行中_Grunning,运行期间大部分情况是在这三种状态间来回切换;
M 的状态可以简化为只有两种:自旋和非自旋;自旋状态,表示 M 绑定了 P 又没有获取 G;非自旋状态,表示正在执行 Go 代码中,或正在进入系统调用,或空闲;
P 结构体中最重要的,是持有一个可运行 G 的长度为 256 的本地环形队列,可以通过 CAS 的方式无锁访问,跟需要加锁访问的全局队列 schedt.runq 相对应;
调度器的启动逻辑是:初始化 g0 和 m0,并将二者互相绑定, m0 是程序启动后的初始线程,g0 是 m0 线程的系统栈代表的 G 结构体,负责普通 G 在 M 上的调度切换 –> runtime.schedinit():负责M、P 的初始化过程,分别调用runtime.mcommoninit() 初始化 M 的全局队列allm 、调用 runtime.procresize() 初始化全局 P 队列 allp –> runtime.newproc():负责获取空闲的 G 或创建新的 G –> runtime.mstart() 启动调度循环;
调度器的循环逻辑是:运行函数 schedule() –> 通过 runtime.globrunqget() 从全局队列、通过 runtime.runqget() 从 P 本地队列、 runtime.findrunnable 从各个地方,获取一个可执行的 G –> 调用 runtime.execute() 执行 G –> 调用 runtime.gogo() 在汇编代码层面上真正执行G –> 调用 runtime.goexit0() 执行 G 的清理工作,重新将 G 加入 P 的空闲队列 –> 调用 runtime.schedule() 进入下一次调度循环。
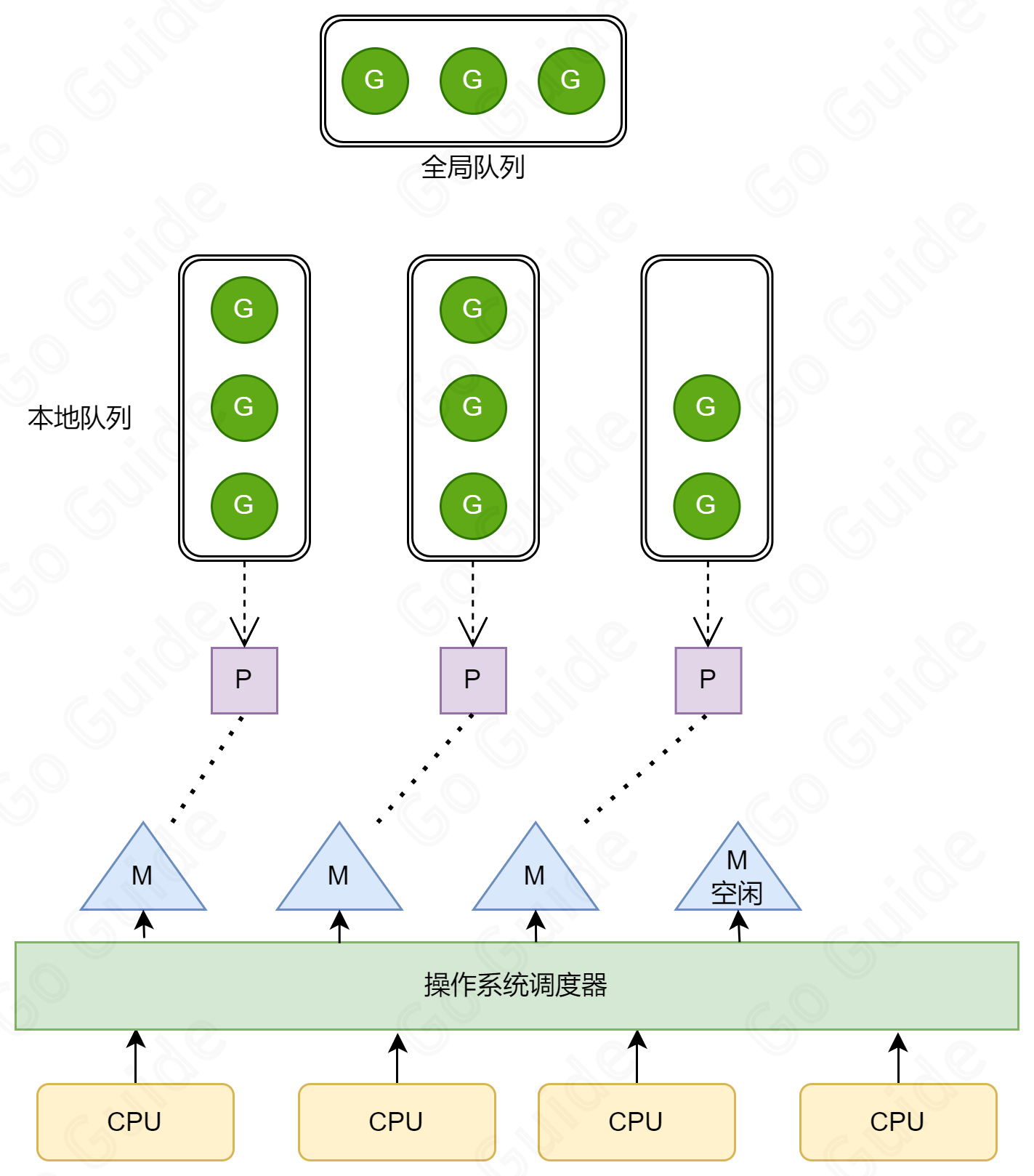
GMP 模型
- G(Goroutine):表示一个 Goroutine,包含栈和相关上下文信息。
- M(Machine):表示一个执行线程,负责将 Goroutine 映射到操作系统的线程上。每个 M 都有自己的调用栈和寄存器状态。(数量是动态的,由调度器决定,根据当前负载动态变化,默认为 10000)
- P(Processor):表示一个逻辑处理器,维护一个处于可运行状态的Goroutine 队列,每个 M 都和一个 P 有关。(数量是固定的)
特点
- 抢占式协调:在协程中需要一个协程主动让出 CPU 下一个协程才能使用 CPU, 而 Goroutine 规定一个 Goroutine 每次最多只能占用 10ms 的 CPU,然后就要切换到下一个, 防止其他协程长时间不被执行。
- 复用线程:Go 语言的调度器会复用线程,而不是每次都创建新的线程,这样可以减少线程创建和销毁的开销,提高性能。
- 工作偷取(Work stealing):当
M没有可运行的G时,会尝试从其他线程绑定的P的本地队列中偷取一半的G来运行,而不是销毁M。 - 交接机制(Hand off):当
G由于系统调用而阻塞时,M会释放绑定的P供其他M使用 - 并行:通过
GOMAXPROCS配置P的数量,从而实现并行执行,P的数量决定了并行度,P的数量等于 CPU 核数时,可以实现最大并行度。
结构
全局队列:是存放所有正在等待的 G。
本地队列:存放当前 P 的 G,每个 P 都有一个队列,用于存放当前的 P 等待和正在运行的 G,最大数量为 256 个。
二者之间的关系(偷取机制)
- 只有本地队列满了,才会存放在全局队列中
- 如果一个本地队列为空,那么他会从其他的本地队列获取一半到自己的本地队列中。