
MyChat
项目来源:https://learnku.com/articles/74274
我对这个项目进行了一些二次开发,完成了一些作者没有做的,或者没有做完的内容,作者写的内容我就不多写了,下面主要是我的学习笔记。主要是相关技术栈入门,以及部分开发的知识。
目前技术栈没有多大变化,也就是原文中的技术栈,只是多了个 docker 部署。
TODO:框架改造:微服务
总体结构
1 | MyChat |
主要技术栈
主要是介绍相关框架,数据库和语言不打算写,可以直接看小林 coding, javaguide 等学习。
Gin
总体参考:
- https://www.zhihu.com/people/xu-xian-sheng-80-10/search?keyword=Gin&pathBefore=%2Fpeople%2Fxu-xian-sheng-80-10
- https://blog.csdn.net/weixin_45177370/article/details/135295839
- https://blog.csdn.net/Mr_XiMu/article/details/127470513
gin 的详细使用可以参考对应的官网:https://gin-gonic.com/zh-cn/
Gin是一个使用Go语言开发的Web框架。 它提供类似Martini的API,但性能更佳,速度提升高达40倍。
Gin 的相关特点有
- 快速:基于 Radix 树 的路由,小内存占用。没有反射。可预测的 API 性能。
- 支持中间件:传入的 HTTP 请求可以由一系列中间件和最终操作来处理。例如:Logger,Authorization,GZIP,最终操作 DB。
- Crash 处理:Gin 可以 catch 一个发生在 HTTP 请求中的 panic 并 recover 它。这样,你的服务器将始终可用。例如,你可以向 Sentry 报告这个 panic!
- JSON 验证:Gin 可以解析并验证请求的 JSON,例如检查所需值的存在。
- 路由组:Gin帮助您更好地组织您的路由,例如,按照需要授权和不需要授权和不同API版本进行分组。此外,路由分组可以无限嵌套而不降低性能。
- 错误管理:Gin 提供了一种方便的方法来收集 HTTP 请求期间发生的所有错误。最终,中间件可以将它们写入日志文件,数据库并通过网络发送。
- 内置渲染:Gin 为 JSON,XML 和 HTML 渲染提供了易于使用的 API。
- 可扩展性:新建一个中间件非常简单
Gin 是基于 net/http 和 context 构成的,这是知乎上小徐先生给出的框架图
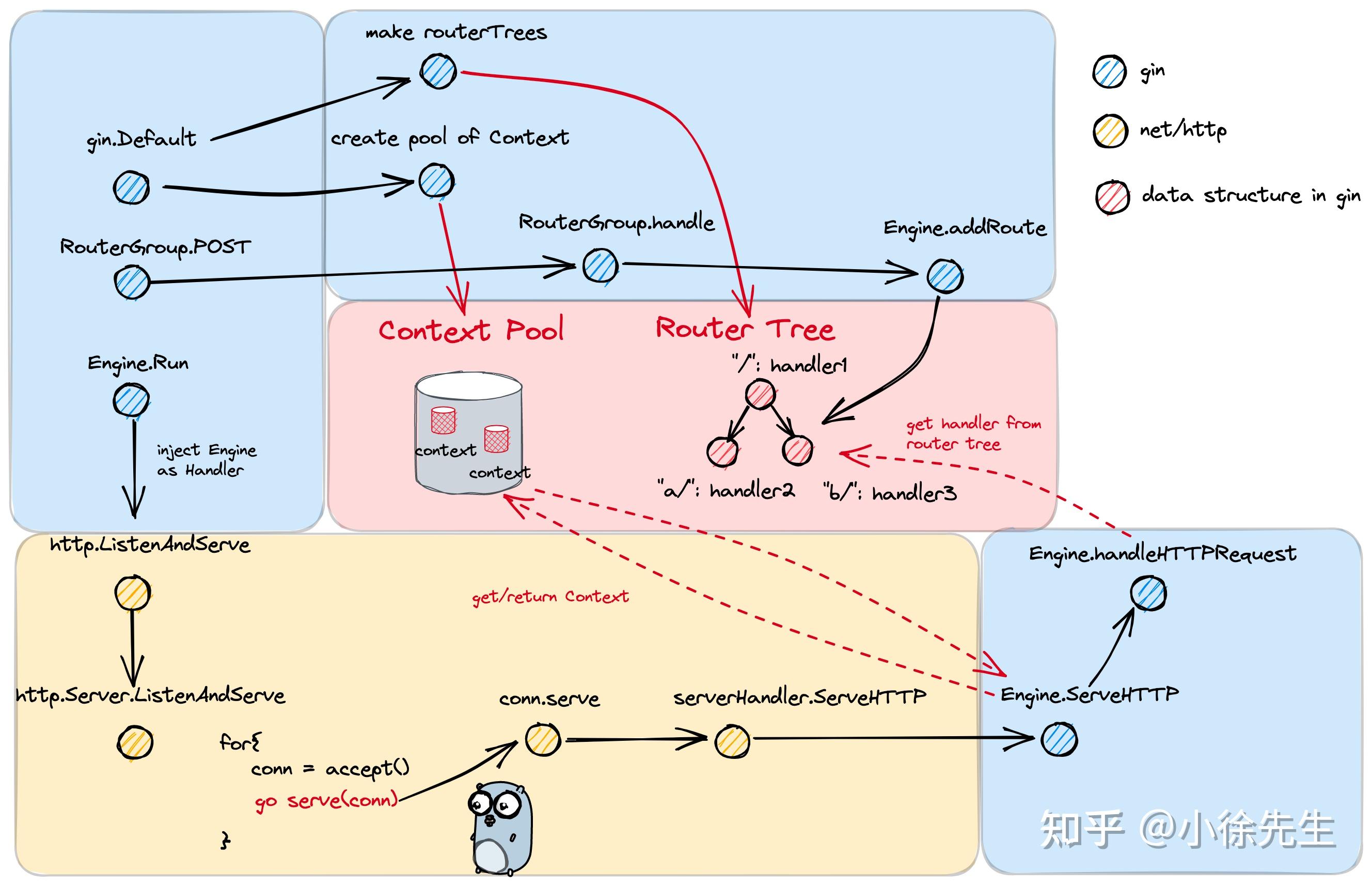
初始化 Engine
1 | type Engine struct { |
注册 middleware
middlerware 本质上也是一个 handler,使用 Use 函数会将新注册的 middleware 自动加入到 HandersChain 中。区别大概就是中间件一般会调用 c.Next(),handler 一般会直接结束请求。
1 | type RouterGroup struct { |
- Handlers:路由组共同的 handler 处理函数链. 组下的节点将拼接 RouterGroup 的公用 handlers 和自己的 handlers,组成最终使用的 handlers 链
- basePath:路由组的基础路径. 组下的节点将拼接 RouterGroup 的 basePath 和自己的 path,组成最终使用的。
- absolutePathengine:指向路由组从属的 Engine
- root:标识路由组是否位于 Engine 的根节点. 当用户基于 RouterGroup.Group 方法创建子路由组后,该标识为 false
注册 handler
基本流程如下,想要详细的代码分析可以看参考链接,都是直接对代码进行分析的:
- 计算出绝对路径:首先拼接出完整路径 absolutePath = basePath + relativePath
- 计算要注册的路由的所有 handlers:拼接 routergroup 已有的 handlers 和注册时的 handlers 得到所有 handlers(深复制)。
- 挂载路由到方法树上:
-
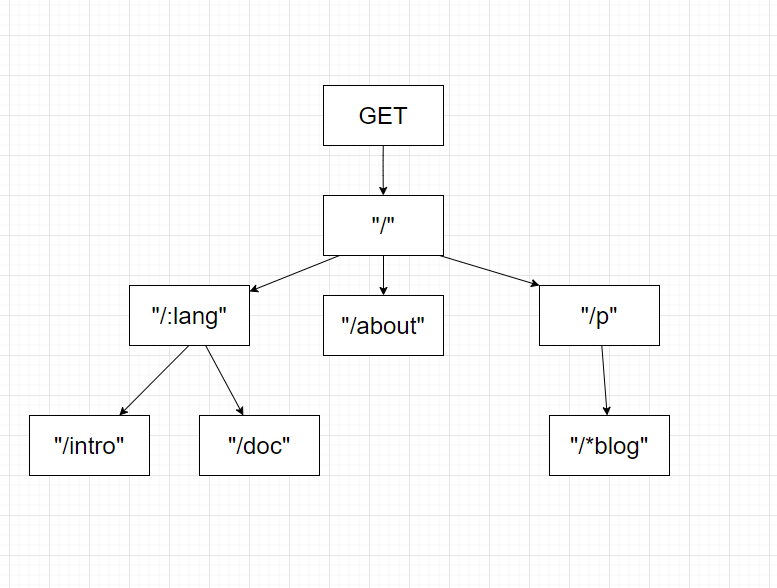
获取对应的方法树(一般来说有九种),每一个方法都有一颗路由树
1
2
3
4
5
6
7
8
9
10
11const (
MethodGet = "GET"
MethodHead = "HEAD"
MethodPost = "POST"
MethodPut = "PUT"
MethodPatch = "PATCH" // RFC 5789
MethodDelete = "DELETE"
MethodConnect = "CONNECT"
MethodOptions = "OPTIONS"
MethodTrace = "TRACE"
) -
将 path 和 handler 挂在对应的方法树上。
-
添加到 radix树上。
-
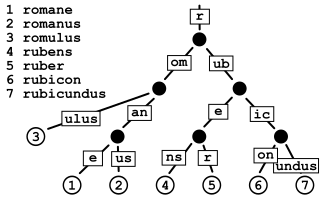
Radix 树
参考:
- https://eslody.github.io/2021/07/10/基数树-Radix-tree-和前缀树-Trie-tree/
- http://taggedwiki.zubiaga.org/new_content/2765ce261c182a6d3cda2da02f01a758
在极客兔兔的手搓 Web 框架中,路由选择也是 trie,不过是使用的字符串,而不是单个字符,并且使用 / 分割,将字符串一个一个进行相应的匹配。
Radix 树是前缀树的一个优化版本,参考 wiki 的定义: 一个基数树、Patricia trie 或 crit bit 树是一种基于 trie 的专门集合数据结构,用于存储一组字符串。与普通 trie 不同,Patricia trie 的边用字符序列标记,而不是单个字符。这些可以是字符序列、如整数或 IP 地址的位序列,或一般任意按字母顺序排列的对象序列。有时基数树和 crit bit 树这两个名称仅用于存储整数的树,而 Patricia trie 则保留用于更通用的输入,但所有情况下的结构工作方式都相同。
A radix tree, Patricia trie/tree, or crit bit tree is a specialized set data structure based on the trie that is used to store a set of strings. In contrast with a regular trie, the edges of a Patricia trie are labelled with sequences of characters rather than with single characters. These can be strings of characters, bit strings such as integers or IP addresses, or generally arbitrary sequences of objects in lexicographical order. Sometimes the names radix tree and crit bit tree are only applied to trees storing integers and Patricia trie is retained for more general inputs, but the structure works the same way in all cases.
此外,在 Gin 路由树中还使用一种补偿策略,在组装路由树时,会将注册路由句柄数量更多的 child node 摆放在 children 数组更靠前的位置。
这是因为某个链路注册的 handlers 句柄数量越多,一次匹配操作所需要话费的时间就越长,被匹配命中的概率就越大,因此应该被优先处理.
- 为什么使用 radix 树而不是 hashmap?hashmap 对静态路由适合而不是适用于动态路由。
启动 http server
本质上是启动 net/http 包下 Handler interface 的实现类,并且调用 http.ListenAndServer 的方法启动。ListenerAndServe 方法本身会基于主动轮询 + IO 多路复用的方式运行,因此程序在正常运行时,会始终阻塞于 Engine.Run 方法,不会返回。
gin Context
在服务端接收到 http 请求时,会通过 Handler.ServeHTTP 方法进行处理. 而此处的 Handler 正是 gin.Engine,其处理请求的核心步骤如下:
- 对于每笔 http 请求,会为其分配一个 gin.Context,在 handlers 链路中持续向下传递
- 调用 Engine.handleHTTPRequest 方法,从路由树中获取 handlers 链,然后遍历调用
- 处理完 http 请求后,会将 gin.Context 进行回收. 整个回收复用的流程基于对象池管理
gin.Context 的定位是对应于一次 http 请求,贯穿于整条 handlersChain 调用链路的上下文,其中包含了如下核心字段:
1 | type Context struct { |
值得注意的是,Context 的复制必须是深拷贝,如果是浅拷贝可能多个协程写同一个区域。
1 | // Context is not goroutine safe and should be copied. |
另外,因为 Gin 的 *gin.Context 内部已经封装了请求的上下文信息(包括 HTTP 请求、响应、参数、生命周期管理等),传递时应当直接使用 Gin 提供的 context,而不要额外创建或随意复制,否则可能导致请求生命周期被破坏,例如:请求已结束但依然访问 context、资源泄露或数据错乱等问题。
context pool
由于 Context 会被经常创建和销毁,为了保证性能和缓解 GC 的压力。Gin 中含有 Context pool 来对 context 进行复用:
- http 请求到达时,从 pool 中获取 Context,倘若池子已空,通过 pool.New 方法构造新的 Context 补上空缺
- http 请求处理完成后,将 Context 放回 pool 中(其中会删除其中所有的逻辑信息,但是物理上还是存在的),用以后续复用
处理流程
- 寻找对应方法的方法树
- 在改方法上找到对应的 handlers
- 将整个 handler chain 注入到 context 中的 handlers 中
- 利用 c.Next()调用函数链请求
- C.Next() 本质上是压栈调用行为,因此在后置位 handlers 链全部处理完成后,最终会回到压栈前的位置,执行当前 handler 剩余部分的代码逻辑.
- handler 的长度被设置为 63,也就是说 handler 调用链的长度一定不会大于 63,当数字比这个大的时候就可以提前退出 for 循环
总结
直接搬运小徐先生的总结:
- gin 将 Engine 作为 http.Handler 的实现类进行注入,从而融入 Golang net/http 标准库的框架之内
- gin 中基于 handler 链的方式实现中间件和处理函数的协调使用
- gin 中基于压缩前缀树的方式作为路由树的数据结构,对应于 9 种 http 方法共有 9 棵树
- gin 中基于 gin.Context 作为一次 http 请求贯穿整条 handler chain 的核心数据结构
- gin.Context 是一种会被频繁创建销毁的资源对象,因此使用对象池 sync.Pool 进行缓存复用
Gorm
gorm 详细的文档可以参考相关文档:https://gorm.io/zh_CN/docs/index.html
1 | go get -u gorm.io/gorm |
models
ORM 通过将 Go 结构体(Go structs) 映射到数据库表来简化数据库交互。 了解如何在GORM中定义模型,是充分利用GORM全部功能的基础。
TODO
密码加盐
参考:
在 Mysql 数据库中,我们经常需要对敏感信息进行加密保护,保证数据的安全。一般破解方法有两种方法:
- 暴力破解:
- 彩虹表:彩虹表就是把常见字符串(特别是常见密码)的哈希值提前算好并存起来的表。(密码学好复杂,看不懂具体实现方法 qwq)
彩虹表是一个用于加密散列函数逆运算的预先计算好的表, 为破解密码的散列值(或称哈希值、微缩图、摘要、指纹、哈希密文)而准备。一般主流的彩虹表都在100G以上。 这样的表常常用于恢复由有限集字符组成的固定长度的纯文本密码。这是空间/时间替换的典型实践, 比每一次尝试都计算哈希的暴力破解处理时间少而储存空间多,但却比简单的对每条输入散列翻查表的破解方式储存空间少而处理时间多。使用加salt的KDF函数可以使这种攻击难以实现。彩虹表是马丁·赫尔曼早期提出的简单算法的应用
比如常见的注册,当用户把账号密码发过来后,我们就可以对密码进行加盐加密,以下面这种形式存储在数据库中,这样大大增强了我们密码的安全性
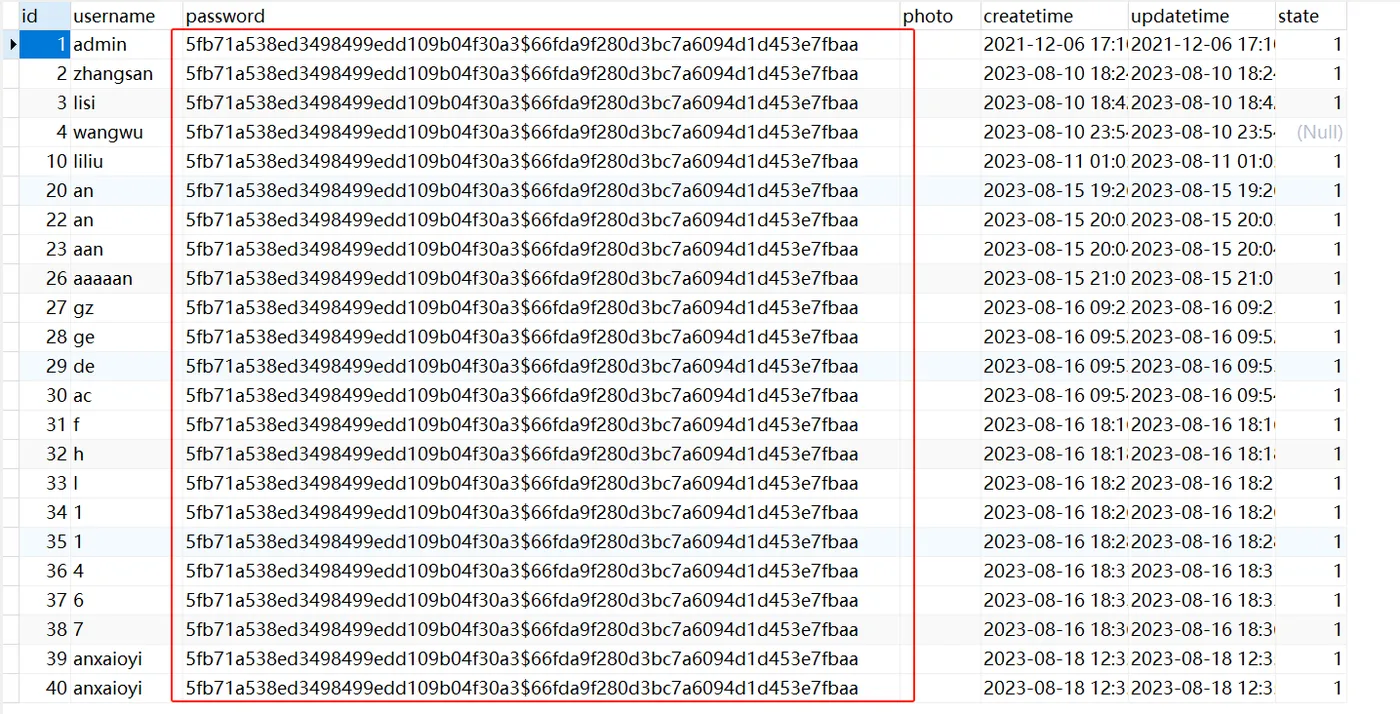
为了应用上述的攻击,加入了加盐加密策略,那么什么是加盐呢?
密码盐值加密是一种增强密码安全性的技术,通过在密码加密前添加随机生成的盐值,确保相同的密码生成不同的哈希值,从而防止暴力破解和彩虹表攻击。
简单来说就是在加密的哈希值上再加入一段字符串来保证密码的安全性,这个随机字符串就是 “盐”。
日志
日志使用的是 Zap Logger,可以参考一下网站:
- https://www.topgoer.com/项目/log/ZapLogger.html
- https://golang.halfiisland.com/community/pkgs/logs/Zap.html#安装
Zap是非常快的、结构化的,分日志级别的Go日志库。
中间件
JWT
jwt 全称:json web token(本身也是 token),其实就是以 json 格式颁发的 web 服务使用的令牌,有了令牌就拥有了访问一些被保护资源的权利。
JSON Web Token (JWT)是一个开放标准(RFC 7519) ,它定义了一种紧凑和自包含的方式, 用于作为 JSON 对象在各方之间安全地传输信息。此信息可以进行验证和信任,因为它是经过数字签名的。JWT 可以使用机密(使用 HMAC 算法)或使用 RSA 或 ECDSA 的公钥/私钥对进行签名。
虽然可以对 JWT 进行加密,以便在各方之间提供保密性,但是我们将关注已签名的Token。签名Token可以验证其中包含的声明的完整性,而加密Token可以向其他方隐藏这些声明。当使用公钥/私钥对对令牌进行签名时,该签名还证明只有持有私钥的一方才是对其进行签名的一方( 签名技术是保证传输的信息不被篡改,并不能保证信息传输的安全 )。
知道了解一个东西之前首先要知道为什么要出现这个东西,是为了解决什么问题引入的:
首先,我们知道在 JWT 出现之前,使用最多的就是 cookie + session 组合,用户成功登录之后,都会在服务端放一个 session,里面包含了用户的基本信息,另外还会给客户端发送一个 session id 用来证明客户端身份。
解决了需要反复验证身份的流程,但是也引入了新的问题:
- 服务器需要保存好 session,而且要做到分布式同步,让每一台机器都能够访问到。
- 扩展性非常差,在微服务里面需要不停的转发消息到不同的服务中,所有的服务都要共享 session 数据
- 传统 Session 基于 Cookie,在跨域 API、移动端 App、第三方服务调用时用起来不灵活。
为了解决以上的问题,JWT 的核心思想:将用户身份信息编码为一个紧凑且自包含的字符串,可以安全地传输并通过验证,服务器本身不需要保存任何状态,只需要验证 token 是否有效即可,客户端来保存这个 token。
JWT 的优缺点如下:
-
有效避免 CSRF(cross site request forgery) 攻击,跨站请求伪造。
-
适合做移动端:
- 状态管理: Session 基于服务器端的状态管理,而移动端应用通常是无状态的。移动设备的连接可能不稳定或中断,因此难以维护长期的会话状态。如果使用 Session 进行身份认证,移动应用需要频繁地与服务器进行会话维护,增加了网络开销和复杂性;
- 兼容性: 移动端应用通常会面向多个平台,如 iOS、Android 和 Web。每个平台对于 Session 的管理和存储方式可能不同,可能导致跨平台兼容性的问题;
- 安全性: 移动设备通常处于不受信任的网络环境,存在数据泄露和攻击的风险。将敏感的会话信息存储在移动设备上增加了被攻击的潜在风险。
-
单点登录友好,也就是上面的分布式问题,即 cookie 跨域。
JWT 也不完全是有效的,不能完全取代 session:
- 注销登录等场景下 JWT 还有效。
- JWT 的续签问题。
- JWT 体积太大。
简单来说,JWT 是为了解决传统 Session 在分布式、微服务和跨平台场景下扩展性差的问题。它的核心是让认证无状态化,把用户身份信息直接放到客户端的 Token 中,服务端只做校验,不保存状态。
优点是无状态、跨平台、支持单点登录,缺点是无法主动注销、续签麻烦、体积较大。
JWT 组成一共有三个部分,分别是 HEADER、PAYLOAD、SIGNTURE,并且使用 . 进行分割。
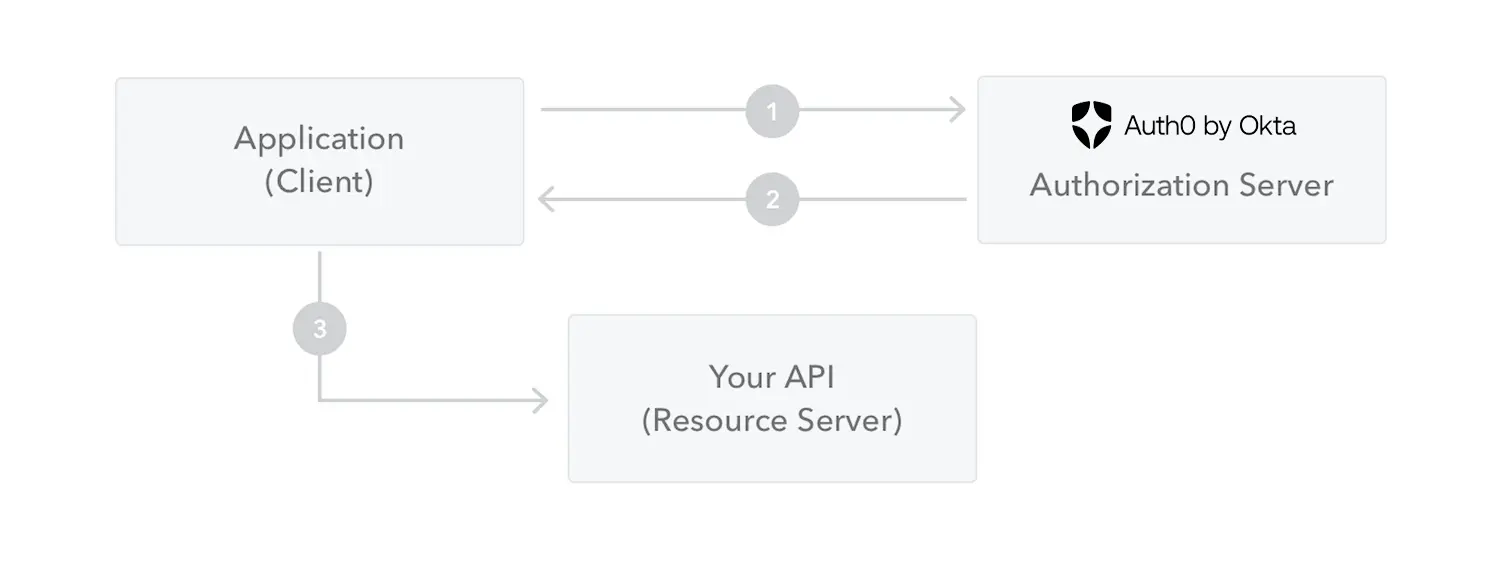
工作流程如上图:
- 用户向服务器发送用户名、密码以及验证码用于登陆系统;
- 如果用户用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT;
- 客户端收到 Token 后自己保存起来(比如浏览器的 localStorage );
- 用户以后每次向后端发请求都在 Header 中带上这个 JWT,格式为
Authorization: Bearer <token>; - 服务端检查 JWT 并从中获取用户相关信息。
-
HEADER:描述 JWT 的元数据,定义了生成签名的算法以及 Token 的类型
1
2
3
4{
"alg": "HS256", // 使用 HMAC-SHA256 签名算法
"typ": "JWT" // 表明这是一个 JWT
}编码之后:
1
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9
-
PAYLOAD:用来存放实际需要传递的数据,包含三种声明:
- registered claims:注册声明,这些是一组预定义的声明,不是强制要求的,而是推荐的,用来提供一组有用的,可互操作的声明。
- iss: jwt签发者
- sub: jwt所面向的用户
- aud: 接收jwt的一方
- exp: jwt的过期时间,这个过期时间必须要大于签发时间
- nbf: 定义在什么时间之前,该jwt都是不可用的.
- iat: jwt的签发时间
- jti: jwt的唯一身份标识,主要用来作为一次性token,从而回避重放攻击
- public claims:使用 JWT 的人可以随意定义这些声明 (可以自己声明一些有效信息如用户的id,name等,但是不要设置一些敏感信息,如密码)。但是为了避免冲突,应该在 JWT注册表中定义它们,或者将它们定义为包含抗冲突名称空间的 URI。
- private claims:这些是创建用于在同意使用它们的各方之间共享信息的习惯声明,既不是注册声明,也不是公开声明( 私人声明是提供者和消费者所共同定义的声明 )。
1
2
3
4
5
6{
"sub": "1234567890",
"name": "John Doe",
"admin": true,
"iat": 1516239022
}编码之后
1
eyJpc3MiOiJleGFtcGxlLmNvbSIsInN1YiI6InVzZXIxMjMiLCJhdWQiOiJteWFwcCIsImV4cCI6MTczOTk5OTk5OSwibmJmIjoxNzM5OTAwMDAwLCJpYXQiOjE3Mzk4OTAwMDAsImp0aSI6ImFiYy0xMjMteHl6IiwidWlkIjo0Miwicm9sZSI6ImFkbWluIiwibmFtZSI6IkFsaWNlIn0
- registered claims:注册声明,这些是一组预定义的声明,不是强制要求的,而是推荐的,用来提供一组有用的,可互操作的声明。
-
Signature:要创建Signature,您必须获取编码的标头(header)、编码的有效载荷(payload)、secret、标头中指定的算法,并对其进行签名。
1
// a-string-secret-at-least-256-bits-long
签名过程为:
1
2
3
4HMACSHA256(
base64UrlEncode(header) + "." + base64UrlEncode(payload),
secret
)secret 是保存在服务器端的,jwt 的签发生成也是在服务器端的,secret 就是用来进行 jwt 的签发和验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个 secret, 那就意味着客户端是可以自我签发 jwt了
-
最终将三个 Base64-URL 拼接起来,并且使用
.拼接在一起,这些字符串可以在 HTML 和 HTTP 环境中轻松传递,比 XML 相比更加紧凑:1
2
3eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.
eyJpc3MiOiJleGFtcGxlLmNvbSIsInN1YiI6InVzZXIxMjMiLCJhdWQiOiJteWFwcCIsImV4cCI6MTczOTk5OTk5OSwibmJmIjoxNzM5OTAwMDAwLCJpYXQiOjE3Mzk4OTAwMDAsImp0aSI6ImFiYy0xMjMteHl6IiwidWlkIjo0Miwicm9sZSI6ImFkbWluIiwibmFtZSI6IkFsaWNlIn0.
Fh23vSJJ8SHP5y3oGlN7rj2CpQp6x5pSmx5nKXjXyZI